본 포스팅은 https://www.deeplearning.ai/ 에서 공개한 무료 gpt 강의의 프롬프팅을 잘 하기 위한 방법을 실습해보고 번역 및 요약해본 포스팅입니다.
질문을 잘하기 위헤서는 모델의 약점을 파악해서
모델의 실수를 줄여나갈 수 있도록 프롬프팅을 하는 편이 확실히 도움된다는 사실을 학습하게 되었습니다.
대주제1. 프롬프팅의 원칙
-원칙1. Write clear and specific instructions
여기서 말하는 clear라는 것은 명확하게라는 뜻 입니다.
이를 short instructions 와 혼동하지 말라는 의미입니다.
clear하고 specific 한 설명문을 작성하기 위한 전략이 필요합니다.
자세한 내용은 세부 전략을 보고 파악하겠습니다.
-원칙1-전략1. delimiters를 사용하자
delimiters는 구분문자 라는 뜻으로
Triple quotes(삼중 따옴표): """
Triple backticks(삼중 백틱): ```
Triple dashes(삼중 대시): ---
Angle brakets(꺾쇠 괄호): <>
XML tags(XML 태그): <tag> </tag>
등을 말합니다.
예를 들어
요약해야하는 내용 :
```
교육의 자주성·전문성·정치적 중립성 및 대학의 자율성은 법률이 정하는 바에 의하여 보장된다.
모든 국민은 직업선택의 자유를 가진다. 모든 국민은 법률이 정하는 바에 의하여 공무담임권을 가진다.
국가는 전통문화의 계승·발전과 민족문화의 창달에 노력하여야 한다.
모든 국민은 근로의 권리를 가진다.
국가는 사회적·경제적 방법으로 근로자의 고용의 증진과 적정임금의 보장에 노력하여야 하며,
법률이 정하는 바에 의하여 최저임금제를 시행하여야 한다.
```이렇게 프롬프트를 생성한다면 ai가 대답할 프롬프트에 delimiters 안에 있는 내용을 "주입"하는 것이 가능해집니다.
이는 뒤에서 보게 될
ai에게 시간을 좀 더 주고 리소스를 쓰게 만들어 좀 더 좋은 판단을 내리도록 하는 전략의 핵심입니다.
-원칙1-전략2. Ask for a structured output
프롬프팅에서는
구조화된 output을 지정하는 것이 가능합니다.
예를 들어 html, json 등으로 지정할 수 있다는 뜻입니다.
"""
Generate a list of three made-up book titles along \
with their authors and genres.
Provide them in JSON format with the following keys:
book_id, title, author, genre.
"""이와 같은 식으로 프롬프트를 생성해서 질문을 할 수 있습니다. 그 결과는?
[
{
"book_id": 1,
"title": "The Lost City of Zorath",
"author": "Aria Blackwood",
"genre": "Fantasy"
},
{
"book_id": 2,
"title": "The Last Survivors",
"author": "Ethan Stone",
"genre": "Science Fiction"
},
{
"book_id": 3,
"title": "The Secret Life of Bees",
"author": "Lila Rose",
"genre": "Romance"
}
]이런 식으로 제공이 됩니다.
챗 gpt는 이러한 구조를 "이미" 이해하고 있습니다.
이는 프로그래밍에서도 사용이 가능하며 우리가 웹에서 사용하는 챗 지피티에도 똑같이 적용됩니다.
-원칙1-전략3. Ask the model to check whether conditions are satisfied
즉, 모델에게 조건들이 충족되었는지 아닌지 체크하는 질문을 해야한다는 뜻 입니다.
예시 텍스트 :
예시 텍스트 = f"""
차 한 잔을 만드는 것은 쉽습니다! 먼저 물을 끓이세요. \
그 동안 찻잔을 준비하고 차(tea) 가방을 넣으세요. \
물이 충분히 뜨겁다면 차 가방 위에 물을 부어주세요. \
차가 우려지도록 조금 기다리세요. \
몇 분 후에 차 가방을 빼내세요. \
원한다면 설탕이나 우유를 맛에 따라 넣어도 됩니다. \
그리고 완성! 맛있는 차 한 잔을 즐길 수 있습니다.
"""프롬프트 :
프롬프트 = f"""
세 개의 따옴표로 묶인 텍스트가 제공됩니다. \
그것이 일련의 지시사항을 포함하고 있다면, \
다음 형식으로 지시사항을 다시 작성하세요:
1단계 - ...
2단계 - ...
...
N단계 - ...
텍스트에 지시사항이 포함되어 있지 않다면, \
그냥 "단계가 제공되지 않았습니다."라고 적으세요.
"""이것은 open ai 에서 제공하는 강의의 예제 프롬프트를 해석한 것 입니다.
~~ 하라는 것을 지시사항이라는 것을 이해하고 있으며
그것이 일련의 지시사항을 포함하고 있다면, 이라는 조건을 붙이고
다음 형식으로 지시사항을 다시 작성하세요:
를 통해서 내가 원하는 포맷을 지정해줍니다.
이런 식으로 if else 처리를 해서 내가 원하는 답을 간결하게 볼 수 있게 되었습니다.
위에서 제공하는 예시 텍스트에 지시하는 느낌이 없는 평서문을 이어 붙인 문장을 주면
No steps provided. 라고만 결과가 나오는 것을 확인할 수 있습니다.
-원칙1-전략4. "Few-shot" prompting
강의에서는
Give successful examples of completing tasks
Then ask model to perform the task 라고 되어 있는데 이를 적절하게 번역하자면
"성공적으로 완료되었던 적은(few) 예시를 통해 질문하라!" 라고 요약할 수 있습니다.
소수의 샘플을 사용하여 모델을 학습시키는 방법입니다. 이러한 학습 방식은 자연어 처리에서도 이용되는 기법입니다.
간단한 예시를 들면 다음과 같습니다.
프롬프트 내용 :
프롬프트 내용
```
당신의 가장 중요한 임무는 일관된 스타일로 답변하는 것 입니다.
<아이> : 인내에 대해서 알려주세요
<할아버지> : 인내란 것은 말이다~
가장 깊은 계곡을 만드는 강은 소박한 봄에서부터 시작되고
가장 웅장한 교향곡은 하나의 음에서부터 시작되며
가장 복잡한 타페스트리는 단 하나의 외로운 실로부터 시작된단다.
<아이> : 그러면 회복력에 대해서 알려주세요
<할아버지> :
```이런 식으로 물어보게 되면 할아버지의 입장으로 대답을 해주게 됩니다.

-원칙2. Give the model time to “think”
모델에게 생각할 시간을 주라는 뜻 입니다.
예를 들자면 이런 뜻입니다.
바로바로 생각나는 것을 질문하는 것은 잘못된 결론으로 달려가는 지름길
이라고 직원이 언급합니다.
우리는 반드시 모델이 최종 답변을 제공하기 전에
관련된 연쇄적인 혹은 시리즈화 시킨 논리적 추론을 요청해야합니다.
모델에게 일을 시킬 때 너무 복잡한 주제의 문제지만
적은 단어로 적은 양의 시간에 문제를 해결하려고 했을 때 잘못된 정보를 얻은 경험이 많을 것 입니다.
반대로 생각해보면, 이는 아무리 뛰어난 인간이라도 할 수 없는 일 입니다.
예를 들어서 천재라고 불리우는 사람한테 선형대수학과 복잡한 통계에 대한 문제를 길가는 중에
대뜸 이 문제 풀 수 있냐고 단 한문장으로 물어본다면
그들은 실수할 수 밖에 없습니다.
그렇기 때문에 우리들은 모델이 좀 더 생각할 시간을 가질 수 있도록 지휘할 필요가 있습니다.
이 말은 ai에게 일을 시킬 때 전산적으로 좀 더 많은 일을 처리할 수 있도록,
당신의 요청을 수행하는데 더 많은 정보를 참조할 수 있도록 질문해야한다는 뜻 입니다.
그 세부 전략과 예제도 함께 보겠습니다.
-원칙2-전략1. Specify the steps required to complete a task
업무를 완료하는데 필요한 특정한 절차를 요구하세요.
예를 들어서 어떠한 동작을 수행할지 1-, 2- 와 같은 식으로 절차를 붙여서 요청을 한다는 뜻 입니다.
예를 들어서 질문을
Question :
"""
다음 동작을 수행하세요:
1 - 세 개의 역따옴표로 구분된 다음 텍스트를 1문장으로 요약합니다.
2 - 요약본을 프랑스어로 번역합니다.
3 - 프랑스어 요약본에서 각 이름을 나열합니다.
4 - 다음 키를 포함하는 json 객체를 출력합니다: french_summary, num_names.
"""이런 형식으로 하게 되면
한번에 하나의 대답을 하는 것이 아니라 최종 답변이 4가 되는 것이고
1, 2, 3의 과정을 거치면서 모델에게 정보가 누적되게 됩니다.
4의 출력에서는 1, 2, 3의 과정의 결과들을 참고할 수 있게 되었습니다.
여기에서 우리는 질문을 하게 될 때 결과물의 형식 뿐만 아니라 각각의 단계에 존재하는 객체들의
타입에 대해서도 정해줄 수 있습니다.
예를 들어서 위의 예제를 들어서 설명하게 되면
<다음 텍스트>, <요약본>, <프랑스어 번역본>, <이름> 등의 타입을 지정할 수 있다는 뜻 입니다.
여기에서 <이름>의 타입을 "첫 요약에서 얻은 리스트에 존재하는 이름들" 이런 식으로 지정해줄 수 있다는 뜻 입니다.
타입을 지정하는 방법은 다음과 같습니다.
# 위의 내용과 이어집니다
다음 정해진 형식을 사용하세요:
텍스트 : <요약의 대상이 될 텍스트>
요약본 : <요약한 내용>
번역본 : <요약한 내용을 번역한 내용>
이름들 : <요약한 내용에 포함되어 있는 이름들의 리스트>
결과물 (JSON) : <"요약본"과 num_이름들을 key로 가진 json>이름이라는 것을 모델이 착각할 수 있기 때문에 이런 식으로 확실하게 지정해주면 모델의 정확도가 올라갑니다.
현재 이름은 원본 텍스트, 요약본, 번역본에 존재하고 있습니다.

이런 식으로 챗 지피티에서도 활용이 가능합니다.
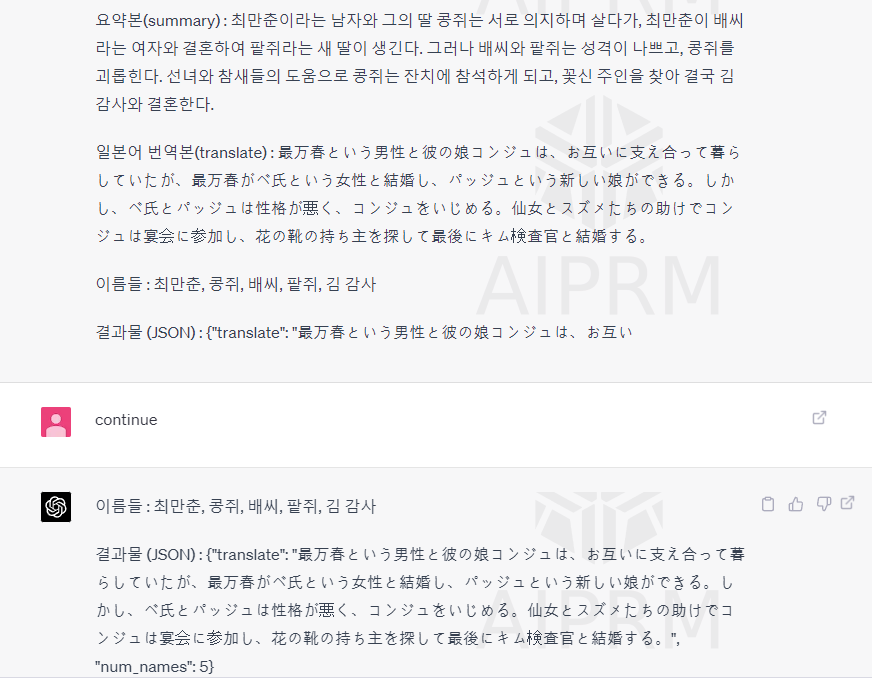
num_name 에 5라고 잘 출력이 되는 모습을 볼 수 있습니다.
-원칙2-전략2. 모델이 결론을 급하게 내기 전에, 스스로 해결책을 찾도록 지시할 것
다음 사진과 같은 예제를 보게 되면 조금만 계산을 꼬아버려도 모델이 실수를 하는 모습을 볼 수 있습니다.
이는 생각보다 너무 빨리 결론을 내려버리기 때문입니다.

위의 사진도 설명을 잘 해낸 것 같지만 올바른 결론을 도출하기 위해서는 좀 더 절차가 필요합니다.
여기에서 학생이 간과한 것은 "평방 피트당 추가로 $10의 유지비용이 발생한다" 라는 점 입니다.
저는 기존에 이런 상황을 만난다면 총 비용을 구성하는 요소들에 포함될 항목들에 대해서 더 자세히 취하는 전략을 사용했는데요, 강의에서 제안한 방식은 상당히 효과적이었습니다.
그렇다면 다음 예제를 살펴보겠습니다.
prompt = f"""
Your task is to determine if the student's solution \
is correct or not.
To solve the problem do the following:
- First, work out your own solution to the problem.
- Then compare your solution to the student's solution \
and evaluate if the student's solution is correct or not.
Don't decide if the student's solution is correct until
you have done the problem yourself.
Use the following format:
Question:
```
question here
```
Student's solution:
```
student's solution here
```
Actual solution:
```
steps to work out the solution and your solution here
```
Is the student's solution the same as actual solution \
just calculated:
```
yes or no
```
Student grade:
```
correct or incorrect
```
Question:
```
I'm building a solar power installation and I need help \
working out the financials.
- Land costs $100 / square foot
- I can buy solar panels for $250 / square foot
- I negotiated a contract for maintenance that will cost \
me a flat $100k per year, and an additional $10 / square \
foot
What is the total cost for the first year of operations \
as a function of the number of square feet.
```
Student's solution:
```
Let x be the size of the installation in square feet.
Costs:
1. Land cost: 100x
2. Solar panel cost: 250x
3. Maintenance cost: 100,000 + 100x
Total cost: 100x + 250x + 100,000 + 100x = 450x + 100,000
```
Actual solution:
"""
response = get_completion(prompt)
print(response)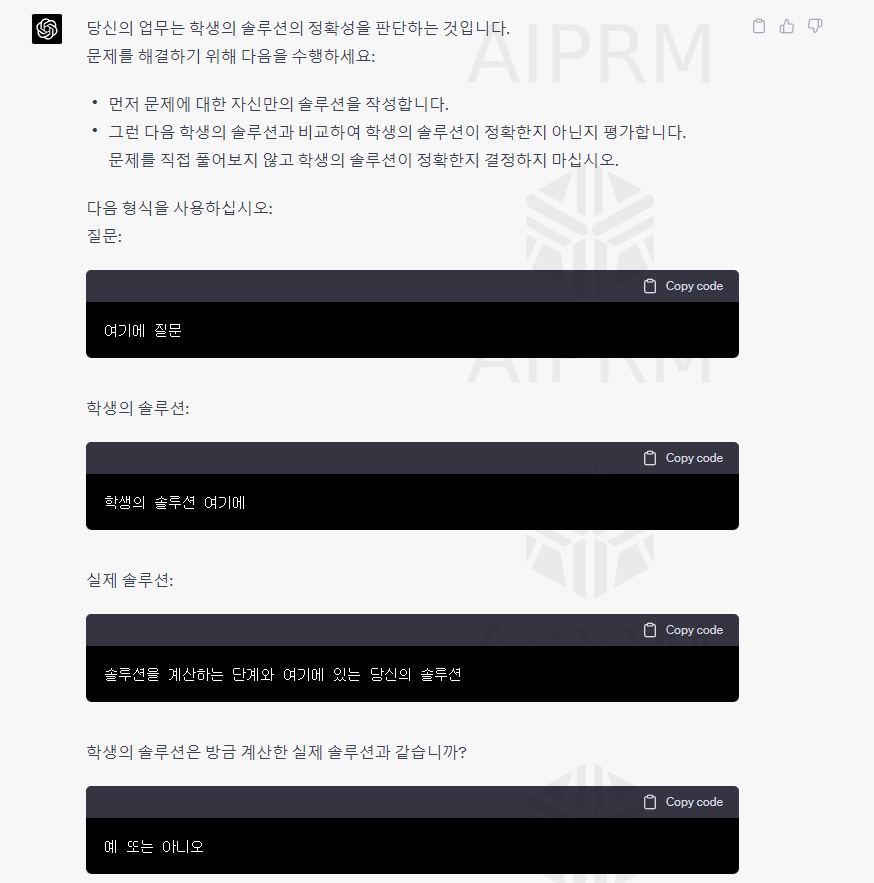
``` ``` 백틱 3개로 감싼 영역이 코드를 입력하는 곳처럼 표시가 되었습니다.
우선 질문까지는 위와 동일합니다.
그런데 여기에서 조건을 달았습니다.
그것은 바로 문제를 직접 풀어보지 않고 학생의 솔루션이 정확한지 결정하지 말라는 것 입니다.
원래 이러한 모델들은 빠르게 결론을 내려는 경향이 있습니다.
그러한 결론을 내는 행위 자체를 지연시킵니다.
이러한 생각하는 방식은 여러 방면으로 응용될 수 있으며 강력합니다.
아까 말했던 "내용 주입"이라는건 다른 무수히 많은 정보들보다 ``` ``` 안의 내용을 우선적으로 점검한다는 뜻 입니다.
지금까지 제공된 내용을 바탕으로 프롬프트를 구성한다면
모델이 제공하는 답변의 정확도가 올라갈 것 입니다.
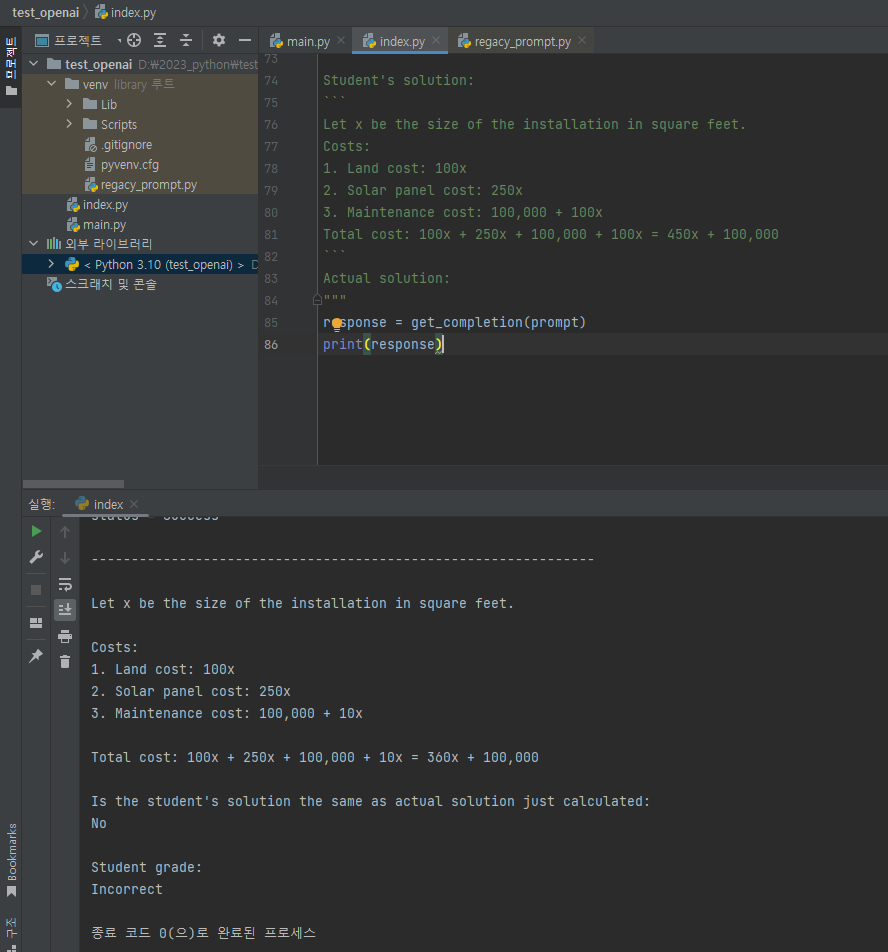
결정을 유보하고 스스로 정리한 정보를 바탕으로 학생이 잘못 되었다는 옳은 판단을 내렸습니다.
대주제2. Model Limitations
여기에서는 세부적인 전략은 없습니다.
이는 현재 모델의 약점, 제한 사항에 대한 내용입니다.
이러한 언어 모델을 사용하여 개발할 때 "모델의 환각(Hallucinations)" 현상이 일어날 수 있음을 생각해야만 합니다.
이 현상은 낯설고 잘 모르는 주제라고 하더라도 대답하려고 그럴듯한 답변을 만드는 과정에서 자주 나타납니다.
모델이 교육을 하면서 방대한 양의 지식에 노출되지만, 이들을 완벽하게 기억하지는 못합니다.
따라서 지식의 경계, 즉 진실과 거짓의 판단부터 정확도에 대한 것들을 의미합니다.
예를 들어서 "에이스 침대"의 "파로마 브릭스 LED 모션베드에 대한 설명"를 요구하면
꽤나 그럴싸하게 말을 지어냅니다.
지금과 같은 경우는 "에이스 침대"는 실제로 존재하는 회사 이름이고
"파로마 브릭스 LED 모션베드"의 경우는 실제로 존재하지만 "시몬스 침대"의 제품입니다.
하지만 모델은 이를 착각하여 설명합니다.
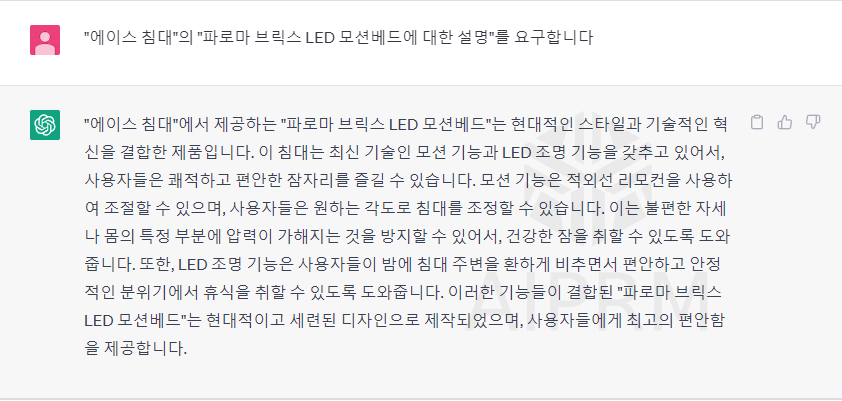
또한 그럴듯한 경우라면 이 세상에 존재하지 않는 상품이라도 그럴듯하게 이야기를 지어냅니다.

이것이 위험한 이유는
"정말로 그럴듯해보여서"
만약에 어떤 업무를 하다가 귀찮은 나머지 더블체크를 하지 않았다면
모델의 환각 현상이 일어났던 부분을 나중에 찾아내기란 많이 힘들 수 있습니다.
그래도 강의에서는 지금까지 배운 원칙들을 중심으로 프롬프팅을 진행하면
이러한 현상을 최대한 막을 수 있고,
이러한 텍스트 기반의 모델이 최신 정보 혹은 무언가를 참고해서
답변을 생성하도록 할 때 가장 좋은 원칙은
1. 먼저 모델에게 관련 인용구를 찾도록 요청하거나
2. 공식문서, 설명서 등의 내용을 긁어와서 모델에게 그 내용은 어떠한 공식문서다, 어떠한 설명서다 설명해주는 방법이 있습니다.
이렇게 또 다른 최신 아티클 혹은 문서를 가져와서 학습 시켰을 경우에는
- 원하는 인용구를 찾아서 ``` ``` 안에 넣도록 합니다.
- 그 인용구를 찾기 전에는 최종 결론을 내리지 않도록 지시합니다.
- 새로운 문서에서 요청한 인용구를 찾고 선결과제를 끝낸 이후에 그 정보를 바탕으로 답변하도록 설정합니다.
이러한 과정들을 통해 모델의 환각 현상을 상당수 줄일 수 있습니다.
다음 포스팅으로는 좀 더 테크닉적인 부분을 다루게 됩니다.
이번 포스팅까지는 코딩을 잘 모르는 일반인이라도 프롬프팅이 무엇이고 어떻게 하면 좋은지에 대한 좋은 이정표가 될 것이라 생각합니다. 좀 더 자세한 정보를 얻고 싶으신 분은 현재 Open Ai 에서 무려 직원분께서 무료로 강의를 제공하니 참조하시면 좋을 것이라 생각합니다.